如何提取图片中的文字并复制
在数字化时代,图像中的文字信息常常需要被提取和利用。无论是从设计图中获取产品规格,还是从旧报纸中摘录重要新闻,能够高效地识别并提取图像中的文字内容变得尤为重要。本文将从多个角度探讨如何识别图像上的文字,并提供一些实用的技巧和工具,帮助读者轻松完成这一任务。

理解ocr技术
光学字符识别(optical character recognition, ocr)是将图像中的文字转换成可编辑和可搜索数据的过程。现代ocr技术依赖于复杂的算法和机器学习模型,能够准确识别各种字体、大小和颜色的文字。了解ocr的基本原理对于选择合适的工具和技术至关重要。
选择合适的ocr工具
市面上有许多ocr工具可供选择,既有免费的开源软件,也有功能强大的商业应用。例如,tesseract是一个由google支持的开源ocr引擎,它提供了广泛的编程接口,适合开发者使用。而adobe acrobat pro dc则是一款面向专业用户的商业软件,其界面友好且识别精度高。根据个人需求和技能水平选择最合适的工具,可以大大提高工作效率。
准备高质量的输入图像
图像质量直接影响ocr的识别效果。清晰度高、对比度强的图像更容易被准确识别。在进行ocr处理之前,可以使用图像处理软件对原始图像进行预处理,如调整亮度、对比度,去除噪点等,以提高ocr的准确性。此外,确保图像中的文字方向正确也很关键,因为大多数ocr工具更擅长处理水平排列的文字。
后处理与优化
即使是最先进的ocr工具,也难以保证100%的识别准确率。因此,在提取文字后,通常还需要进行人工校对和修正。这一步骤虽然耗时,但却是保证最终文本质量的重要环节。同时,对于某些应用场景,可能还需要进一步格式化提取的文字,如添加换行符、段落标记等,以便于后续编辑或阅读。
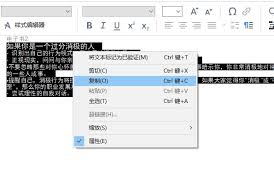
实际操作案例
假设你需要从一张扫描的书籍页面中提取文字内容。首先,你可以使用adobe acrobat pro dc打开这张扫描件,并通过其内置的ocr功能自动识别图像中的文字。接着,检查识别结果是否有误,必要时手动修改。最后,将文本导出为所需的格式(如pdf、word文档),即可完成整个过程。
结语
识别图像中的文字是一项既实用又具挑战性的任务。通过合理选择ocr工具,优化输入图像质量,并进行必要的后处理,我们可以有效地完成这项工作。随着技术的进步,未来ocr技术将变得更加智能和便捷,让我们拭目以待。