Rank函数使用方法介绍
在数据处理和分析中,rank函数是一个非常有用的工具,它可以帮助我们确定数据集中的数值排名。无论是在excel、sql还是编程语言如python中,rank函数都有其独特的应用方式和价值。本文将从多个维度详细介绍rank函数的使用方法。
1. 基本概念
rank函数的主要功能是根据数值的大小对数据进行排序,并赋予每个数值一个排名。排名的类型可以分为几种:
- 普通排名:相同的数值会得到相同的排名。
- 密集排名:相同的数值会得到相同的排名,但下一个不同的数值会跳过相应的排名位数。
- 平均排名:相同的数值会得到相同的排名,但排名数值是这些相同数值所占据位置的平均值。
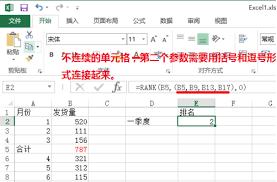
2. 在excel中的使用
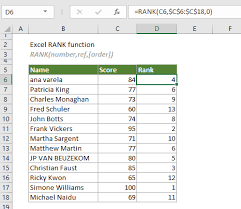
在excel中,rank函数是一个非常常用的函数,用于对数据进行排名。其基本语法为:
```excel
rank(number, ref, [order])
```
- number:要排名的数值。
- ref:包含数据的数组或数据范围。
- [order]:可选参数,0或省略表示降序排名,1表示升序排名。
示例
假设有一列数据a1:a5,分别为5, 3, 8, 3, 7。
```excel
=rank(a1, a1:a5, 0)
```
该公式会返回5在这列数据中的降序排名。
3. 在sql中的使用
在sql中,虽然没有直接的rank函数,但可以通过窗口函数实现类似的功能。常用的窗口函数包括`rank()`, `dense_rank()`, 和 `row_number()`。
rank()
`rank()`函数提供的是普通排名。如果两个数值相同,它们会得到相同的排名,但下一个数值的排名会跳过相应的位数。
```sql
select column_name,
rank() over (order by column_name desc) as rank
from table_name;
```
dense_rank()
`dense_rank()`函数提供的是密集排名。如果两个数值相同,它们会得到相同的排名,但下一个数值的排名不会跳过。
```sql
select column_name,
dense_rank() over (order by column_name desc) as dense_rank
from table_name;
```
row_number()
`row_number()`函数提供的是行号,即使数值相同,每行也会有一个唯一的序号。
```sql
select column_name,
row_number() over (order by column_name desc) as row_num
from table_name;
```
4. 在python中的使用
在python中,虽然没有内置的rank函数,但可以通过pandas库轻松实现类似的功能。pandas提供了`rank()`方法,可以应用于dataframe或series对象。
示例
```python
import pandas as pd
创建一个dataframe
data = {⁄'values⁄': [5, 3, 8, 3, 7]}
df = pd.dataframe(data)
使用rank()方法
df[⁄'rank⁄'] = df[⁄'values⁄'].rank(method=⁄'dense⁄', ascending=false)
print(df)
```
在这个示例中,`method=⁄'dense⁄'`表示使用密集排名,`ascending=false`表示降序排名。
5. 应用场景
rank函数的应用场景非常广泛,包括但不限于:
- 学生成绩排名:根据分数对学生进行排名。
- 销售业绩分析:根据销售额对销售人员进行排名。
- 体育比赛:根据成绩对运动员进行排名。
- 市场分析:根据市场份额对竞争对手进行排名。
6. 注意事项
在使用rank函数时,需要注意以下几点:
- 空值处理:不同的软件或库对空值的处理方式可能不同,需要提前了解并处理。
- 数据范围:确保引用的数据范围正确,避免遗漏或重复数据。
- 排名方法选择:根据实际需求选择合适的排名方法,如普通排名、密集排名或平均排名。
通过以上介绍,相信你已经对rank函数有了全面的了解。无论是在excel、sql还是python中,rank函数都是一个非常强大的工具,能够帮助你更好地进行数据处理和分析。








